
Pasikartojimų analizė (Recurrence Analysis Function, ReAF). Detalų ReAF aprašą žr. publikacijoje Hoenen (2018). ReAF vizualizavimo tikslas yra naudojant pasikartojimus apibūdinti teksto kompoziciją kaip bardinę-ikiliteratūrinę arba kaip literatūrinę. Nors paieškas apsunkina nenuosekli tekstų ortografija, lemų pasikartojimų analizė rodo, kad Donelaičio tekstus neabejotinai galima priskirti literatūrinei kompozicijai.
ReAF:
Pavasario linksmybės,
Vasaros darbai,
Rudenio gėrybės,
Žiemos rūpesčiai,
Fortsetzung,
Pričkaus pasaka apie lietuvišką svodbą,
Lapės ir gandro česnis,
Rudikis jomarkininks,
Šuo didgalvis,
Pasaka apie šūdvabalį,
Vilks provininks,
Aužuols gyrpelnys
Žodžių debesis (wordcloud). Vienas iš populiariausių vizualizavimo būdų skaitmeninėje erdvėje yra žodžių debesis. Vis dėlto jis suteikia tik apytikrį dažniausiai pasikartojančių žodžių vaizdą. Donelaičio tekstų debesis sugeneruotas lemų pagrindu. Pagalbiniai žodžiai (remiantis kalbos dalių pažymomis gramatinėje anotacijoje) nebuvo įtraukti. Grafikas sukurtas Python programavimo kalba.

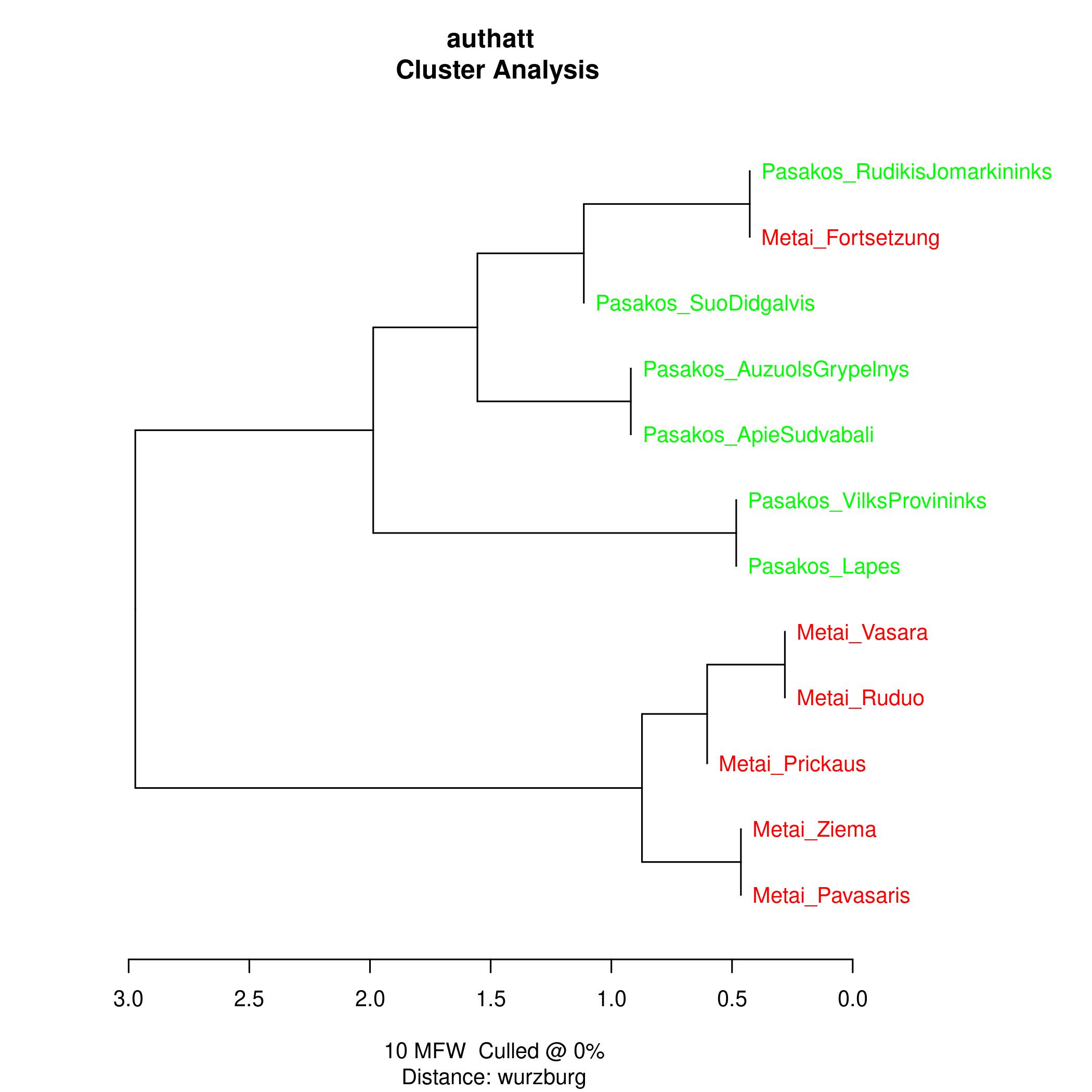
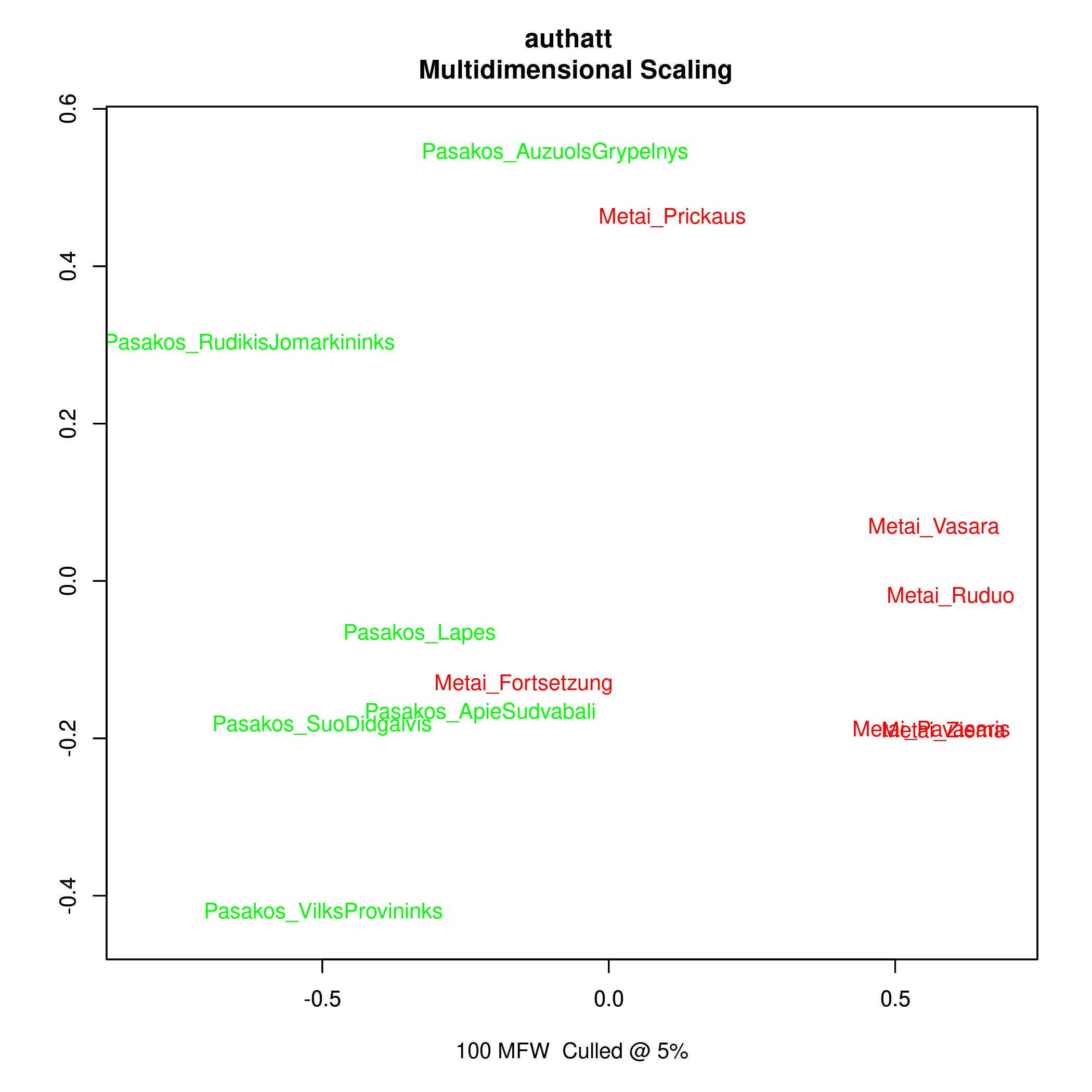
Stilometrija tiria įvairių tekstų ir autorių stilių statistinių duomenų pagrindu. Stilometrija išpopuliarėjo, kai ją taikant buvo nustatyta iki tol anoniminių tekstų autorystė. Naudojant stylo R packet pagal dažniausiai vartojamas lemas buvo siekiama nustatyti Donelaičio tekstų tarpusavio panašumus. Apskritai kalbant, pasakėčios ir Metai labiausiai nutolę vienas nuo kito, bet „Fortsetzung“ tekstas artimesnis pasakėčioms. Įtakos tokiems rezultatams galėjo turėti ir tekstų apimtis. Dažniausiai vartojami žodžiai turinio panašumo paprastai neatspindi, nes tai būna funkciniai žodžiai. Kiek kitoks požiūris į tuos pačius duomenis, vad. multidimensional scaling, kur atstumai tarp tekstų pateikti dvimatėje erdvėje, rodo panašius rezultatus.
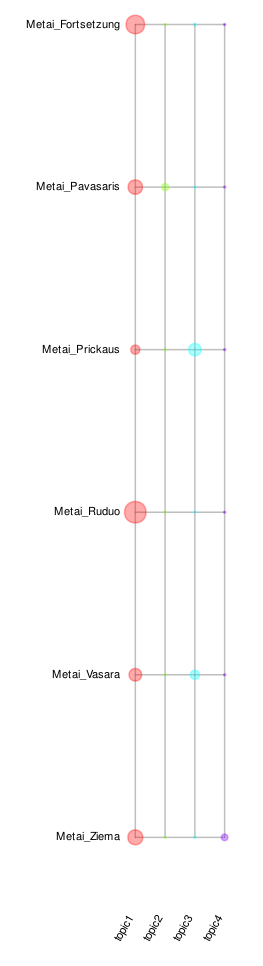
Temų modeliavimas (topic models). Metodas, kuris randa tekstyne statistiškai panašiai pasiskirsčiusias žodžių grupes, t. y. tekstams bendrus bruožus. Tokios žodžių grupės vadinamos temomis (topics). Svarbu tai, kad vienas žodis gali būti kelių skirtingos apimties temų dalis. Vienintelis temų modeliavime reikalingas parametras yra galimų temų skaičius. Modeliuojant Metus (lemas) ir paprastumo dėlei numatant keturias temas, gaunamas žemiau pateiktas grafikas. Kiekvieną temą apibūdina tokie žodžiai (čia pateikiama dešimt svarbiausių):
topic1: savo, būti, būras, ponas, dievas, reikėti, žinoti, pasidaryti, kartas, padaryti
topic2: pulkas, lėlė, austi, kopinėti, nuogas, oras, vanduo, skranda, padėti, trūsas
topic3: krizas, česnis, šventas, matyti, enskys, bjaurus, ranka, svodba, stalas, šokti
topic4: amtsrotas, varna, kakalys, šiltas, šaltyšius, mylėti, metas, klastuoti, žiemys, tamsa
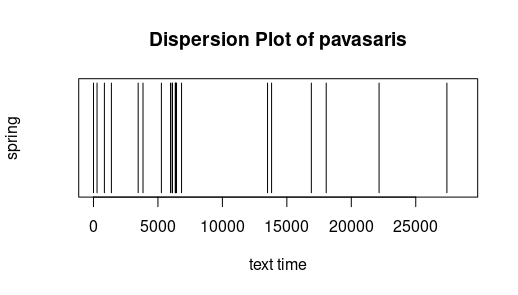
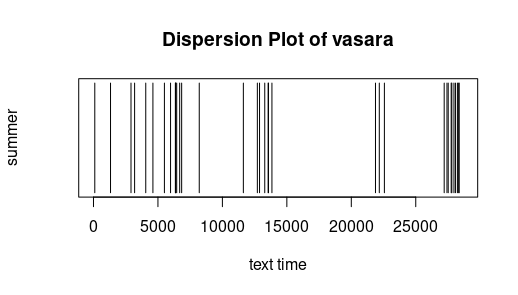
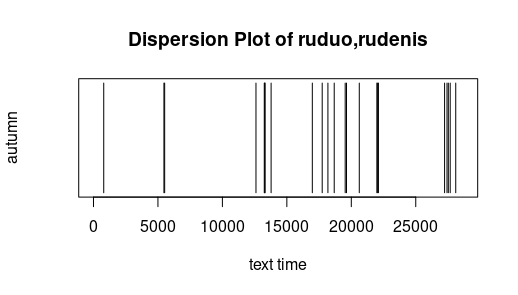
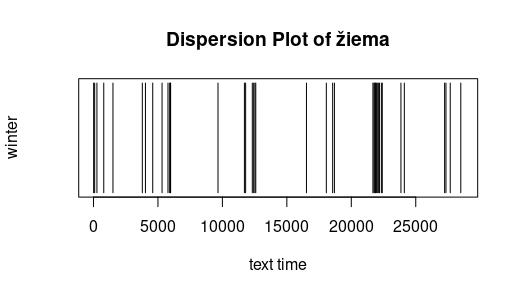
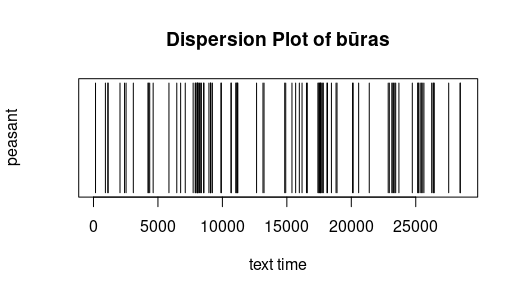
Pasiskirstymas (dispersion). Žemiau pateikti labai paprasti grafikai rodo, kur tekste vartojamas tam tikras žodis. X ašyje (horizontali) pažymėtas „teksto laikas“ (text time), t. y. su kiekviena leksema (žodžiu ar skyrybos ženklu) didėjantis skaičius nuo teksto pradžios iki pabaigos. Kitaip tariant, šimtoji teksto leksema teksto laiko linijoje pažymėta skaičiumi 100. Ištirtas Metų (išskyrus Pričkaus pasaką) pasiskirstymas. Iš grafikų matyti, kad būras veikia visus metus, o metų laikai minimi ne tik atitinkamų dalių pavadinimuose. Laisvai pagal Jockers (2014).

 |
|  |
| 