
Recurrence Analysis Function (ReAF): Eine genaue Beschreibung der ReAF finden Sie in der Publikation Hoenen (2018). Der Sinn dieser Visualisierung liegt im Wesentlichen darin, Redundanz zu nutzen, um
den Entstehungsmodus eines Textes als bardisch-vorschriftlich oder schriftlich zu charakterisieren. Obgleich eine variable Orthographie Redundanz verschleiern kann, ergaben auch die lemmatischen Redundanzanalysen der Texte
des Donelaitis keine Anhaltspunkte von etwas anderem als schriftlicher Entstehung auszugehen.
ReAFs:
Pavasario linksmybės,
Vasaros darbai,
Rudenio gėrybės,
Žiemos rūpesčiai,
Fortsetzung,
Pričkaus pasaka apie lietuvišką svodbą,
Lapės ir gandro česnis,
Rudikis jomarkininks,
Šuo didgalvis,
Pasaka apie šūdvabalį,
Vilks provininks,
Aužuols gyrpelnys
Wordcloud: Eine Wortwolke gehört zu den beliebtesten Visualisierungen im digitalen Raum. Sie ermöglicht jedoch nur einen approximativen Eindruck der durch Häufigkeit besonders hervortretenden Worte eines Textes.
Bei der Generierung dieser Wordcloud wurden nur die Lemmata betrachtet und gleichzeitig alle nicht Inhaltswörter (per Wortarttag) ausgeschlossen. Produziert wurde die Graphik mit Python.

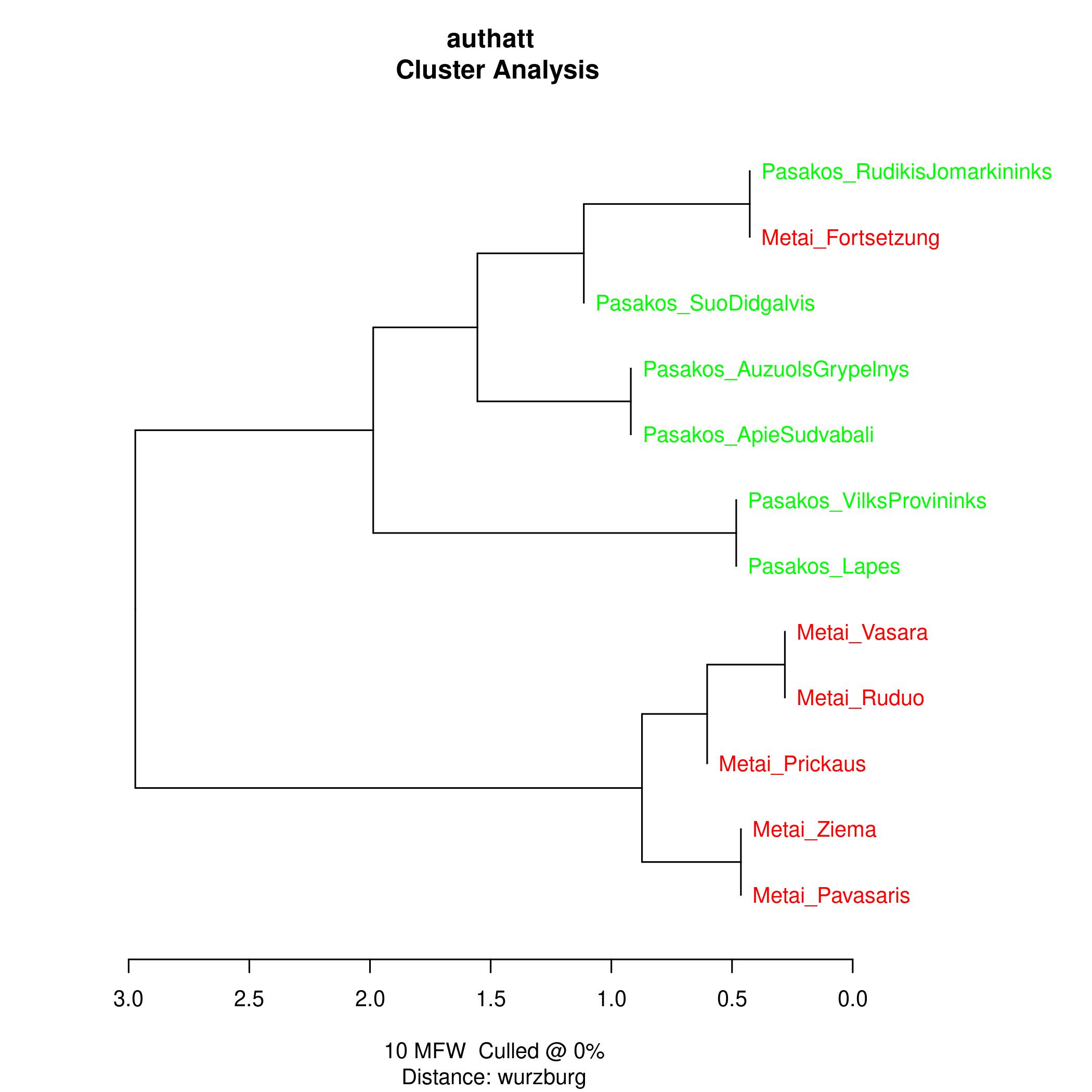
Stilometrie: Die Stilometrie untersucht Stile verschiedener Texte oder Autoren anhand statistischer Merkmale und hat von sich reden gemacht als sie entscheidend dazu beitrug unbekannte Texte Autoren zuzuweisen.
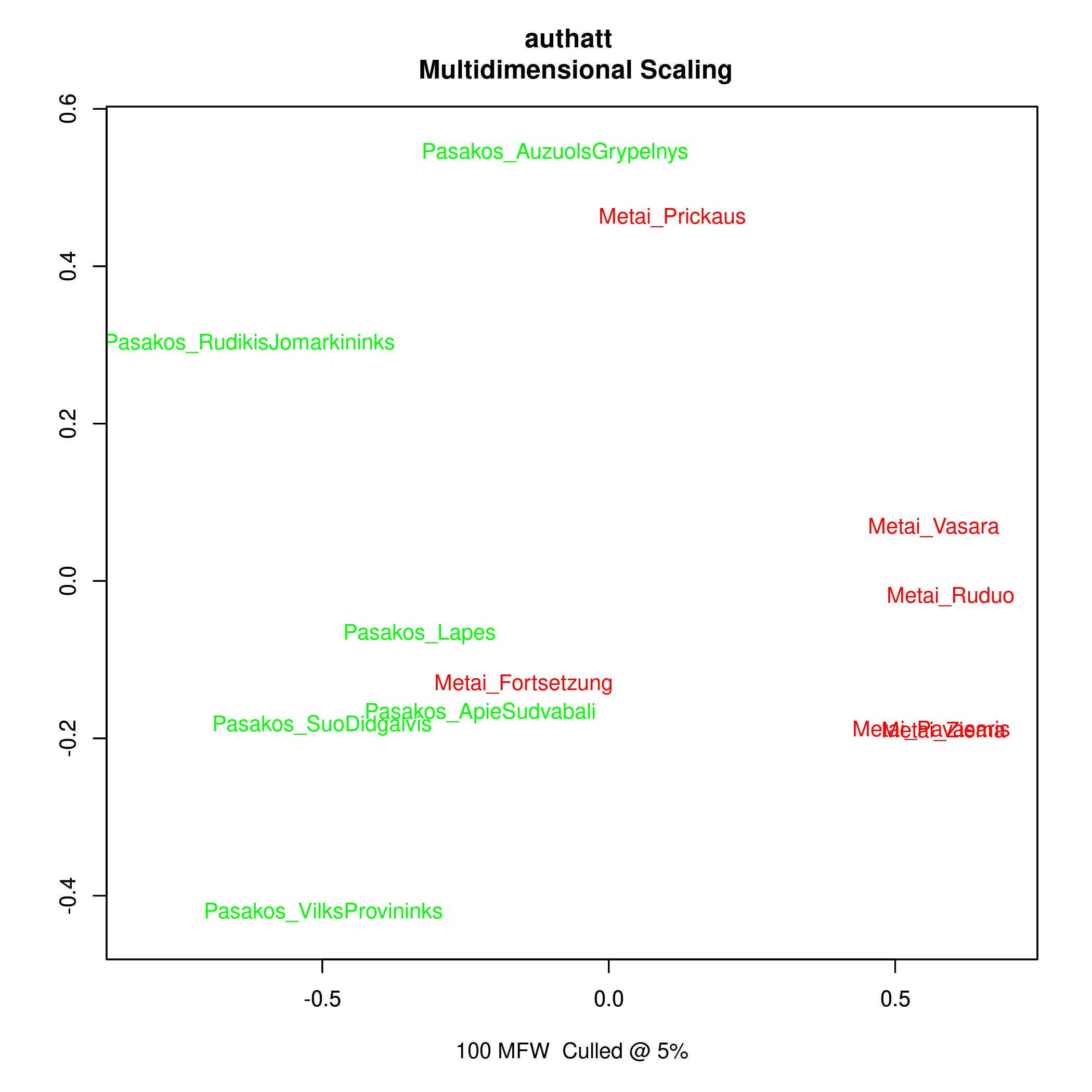
In diesem Fall untersuchen wir mittels des R Pakets stylo, wie sehr sich die Texte anhand des Gebrauchs ihrer häufigsten Lemmata ähneln. Generell ist zu sehen, dass die Fabeln und der Zyklus Metai auseinanderliegen, dass aber
die kürzeren späteren Teile, insbesondere die Fortsetzung eine Tendenz zu den Fabeln aufweisen. Dies kann u.a. durch ihre Länge beeinflusst sein. Es spiegeln sich in der Regel in den häufigsten Wörtern keine inhaltlichen Ähnlichkeiten
wider, da es sich um Funktionsworte handelt. Auch mit einer etwas anderen Sicht auf dieselben Daten (dem sog. multi dimensional scaling) wobei die Texte entsprechend ihrer Distanzen in einen zweidimensionalen Raum
abgebildet werden, erscheinen die Erkenntnisse ähnlich.
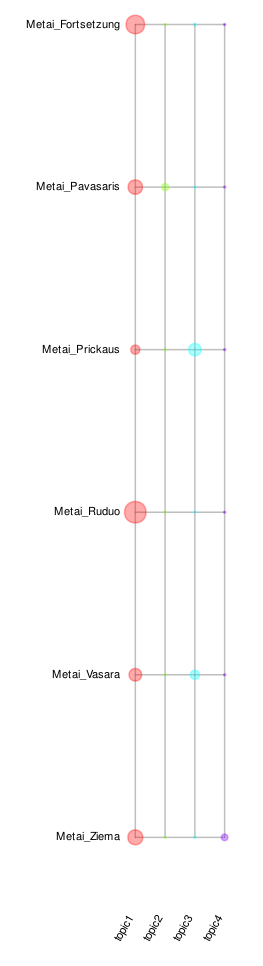
Topic Models: Topic Modelle sind ein Verfahren mit dem Wortgruppen ähnlicher statistischer Verteilung innerhalb eines Textcorpus aufgespürt werden. Dabei werden diese Wortgruppen als topics (Themen) bezeichnet.
Die Besonderheit ist, dass ein Wort unterschiedlich stark an verschiedenen Themen beteiligt sein kann. Der einzige Parameter, den man zum Erzeugen eines Topic Models benötigt ist die Anzahl angenommener Themen im Corpus.
Analysiert man so die Metai (Lemmata) und nimmt der Einfachheit halber 4 Themen an, ergibt sich die folgende Graphik. Die Themen sind hierbei durch folgende Worte (nur wichtigste 10 pro Thema) charakterisiert:
topic1: savo, būti, būras, ponas, dievas, reikėti, žinoti, pasidaryti, kartas, padaryti
topic2: pulkas, lėlė, austi, kopinėti, nuogas, oras, vanduo, skranda, padėti, trūsas
topic3: krizas, česnis, šventas, matyti, enskys, bjaurus, ranka, svodba, stalas, šokti
topic4: amtsrotas, varna, kakalys, šiltas, šaltyšius, mylėti, metas, klastuoti, žiemys, tamsa
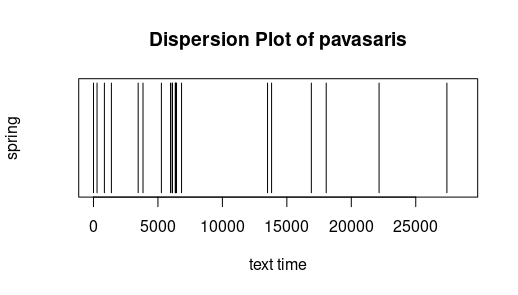
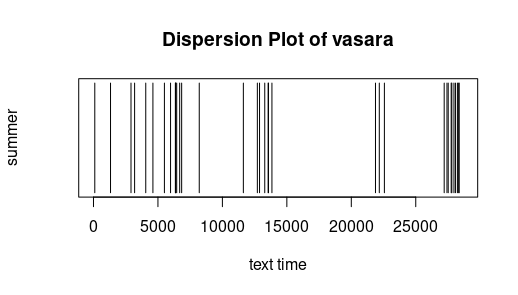
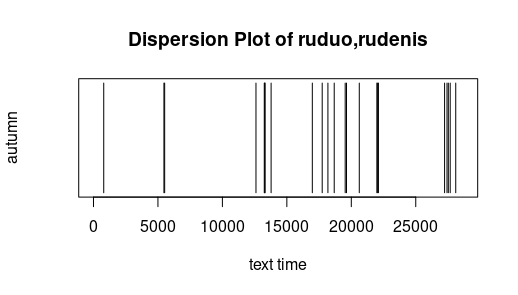
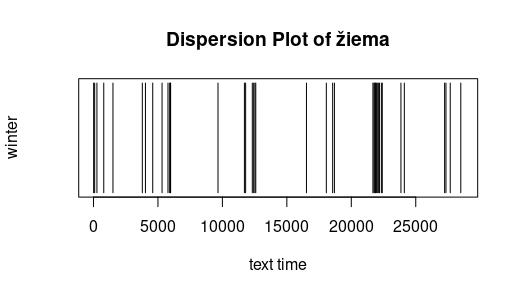
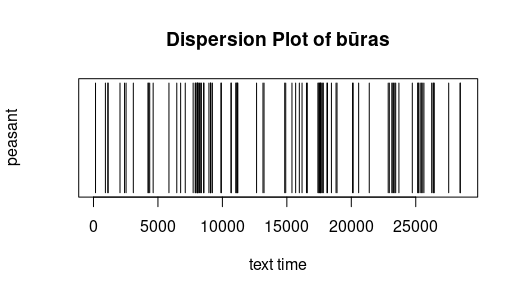
Dispersion: Die folgenden sehr einfachen Graphiken geben an, wo ein bestimmtes Wort in einem Text vorkommt. Die X-Achse ist dabei die "Textzeit", d.h. mit jedem Token (Worte oder Interpunktionszeichen) bewegt sich der
Textzeitzeiger wenn man so will einen Schritt weiter. Das 100ste Wort ist mit anderen Worten dasjenige bei Textzeit 100. Text für die Untersuchung sind die Lemmata der Metai (ohne Fritzens Erzählungen). Es fällt auf, dass der Bauer zu jeder
Jahreszeit aktiv ist und dass diese nicht nur in ihren Kapiteln besprochen werden. Frei nach Jockers (2014)

 |
|  |
| 