1. Vorüberlegungen:
1.1. Historische Sprachveränderungen, die auf die Wirkung von Lautgesetzen zurückzuführen
sind, lassen sich aufgrund ihrer inneren Regelhaftigkeit mit Computerprogrammen
vergleichen: Bei beiden geht es ständig um eindeutige Bedingungen und eindeutige
Folgen, und bei beiden spielt die relative Abfolge von Verarbeitungsschritten, die
"relative Chronologie" eine entscheidende Rolle. Es liegt deshalb nahe, zu überprüfen,
inwieweit konkrete (bezeugte) lautliche Veränderungsprozesse durch ein Computerprogramm
"abgebildet" werden können, das den Weg von älteren "Vorformen" (als "Inputvariablen")
zu jüngeren Lautgestalten (als "Outputvariablen") nachzeichnet. Ein solches Programm
müßte zugleich als Maß dienen können, um festzustellen, ob die zwischen bestimmten
Sprach(stuf)en bestehenden lautgesetzlichen Verbindungen stringent und vollständig
ermittelt sind; Voraussetzung wäre, daß das Programm selbst stringent den tatsächlichen
Gegebenheiten folgend programmiert ist. Soweit die tatsächlichen Gegebenheiten,
insbesondere die relative Chronologie, noch nicht im einzelnen geklärt sind, kann
die Ausarbeitung des Programms, verbunden mit einem ständigen Austesten am Material,
ihrerseits zum sprachwissenschaftlichen Erkenntnisgewinn beitragen. — Auch der
umgekehrte Weg der (internen) Rekonstruktion (als Schluß von einer historisch jüngeren
auf eine zugrundeliegende ältere Form) müßte für ein solches Programm abbildbar
sein, allerdings nur insoweit, als kein irreversibler Lautwandel überbrückt werden
muß. So ist z.B. die Entwicklung von ahd. ein zu nhd. ein [ain] und
von ahd. drî zu nhd. drei [drai] durch einen einfachen Regelapparat
abbildbar, der Rückschluß von nhd. ein und drei auf die jeweilige
ahd. Vorform ist jedoch ohne zusätzliche Informationen (z.B. aus Dialekten oder
verwandten Sprachen) nicht möglich, nachdem älteres ei und ī in
[ai] zusammengefallen sind. — Eine natürliche Grenze für ein Computerprogramm,
das Lautgesetze abbilden soll, ergibt sich aus der Wirkung von Analogien (Ausgleichserscheinungen
syntagmatischer oder paradigmatischer Art), die im Laufe der sprachgeschichtlichen
Entwicklung zu jeder Zeit eintreten können.
1.2. Mit dem vedischen Altindischen und dem altiranischen Avestischen sind uns zwei
Sprachen verfügbar, die geradezu ideale Bedingungen für die Erarbeitung und Austestung
eines die Lautgesetze abbildenden Computerprogramms bieten: Beide haben sich von
der gemeinsamen Vorstufe, dem Urindoiranischen, ungefähr gleich weit wegentwickelt,
und die dabei auftretenden Lautgesetze sind weitgehend bekannt. Zudem steht das
überlieferte Material beider Sprachen für eine Auswertung durch den Computer bereits
zur Verfügung (s. dazu weiter unten). Hier setzt das Projekt "Avesta und Rigveda:
Elektronische Auswertung" (AUREA) an, das derzeit an der Universität Frankfurt
mit Unterstützung der Deutschen Forschungsgemeinschaft realisiert wird. Sein Ziel
ist es, nicht nur die Entwicklung der beiden Einzelsprachen elektronisch abzubilden,
sondern auch deren gegenseitiges Verhältnis (im Sinne eines Dreiecksbezugs zwischen
ihnen und dem Urindoiranischen) einer digitalen Überprüfung zugänglich zu machen.
1.3. Eine Erschwernis ergibt sich nun freilich durch die unterschiedlichen Überlieferungsbedingungen
beider Sprachen: Für das Vedische (des Rigveda) ist zu bedenken, daß der schriftlich
tradierte Text in mancherlei Hinsicht nicht die Originalgestalt der Hymnen widerspiegelt,
indem durch redaktionelle Bearbeitung (Diaskeuase) in erheblichem Maße Sandhierscheinungen,
aber auch andere Veränderungen in ihn eingedrungen sind. Soweit sie regelmäßig
sind, können und müssen die Sandhierscheinungen ihrerseits als (jüngste) lautgesetzliche
Veränderungen im Programm berücksichtigt werden. Im Falle des Avestischen ist
davon auszugehen, daß die in einem äußerst exakten Alphabet niedergeschriebene
Textsammlung alle Einzelheiten der phonetischen Realisierung widerspiegelt, so daß
die Regelmechanismen, die zwischen der für die Sprachgeschichte vornehmlich relevanten
phonologischen Grundstruktur und der phonetischen Realisation angesiedelt sind,
ebenfalls in das Programm integriert werden müssen.
2. Zielsetzungen, Probleme und mögliche Verfahren des jetzt anlaufenden Projekts
seien zunächst an einigen Beispielen illustriert. Aus der Menge derjenigen altavestischen
und vedischen Wortformenpaare, die sich als etymologisch identisch, d.h., von einer
gemeinsamen urindoiranischen Vorform ausgehend auffassen lassen, und sich lediglich
durch eine Abfolge unterschiedlicher lautgesetzlicher Veränderungen auseinanderentwickelt
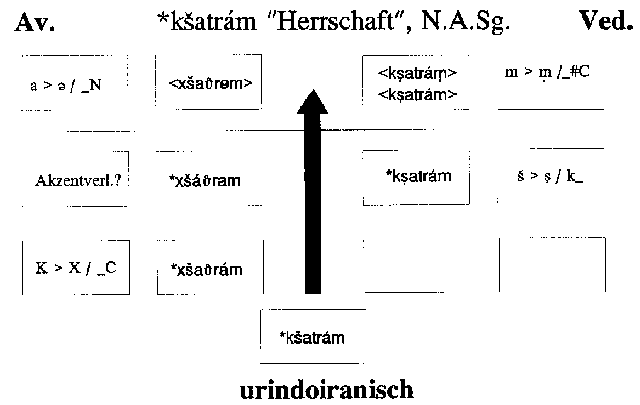
haben, können als willkürlich ausgewählte Beispiele etwa die Formen altav.
xšaϑrəm ≈ ved. kṣatrám "Herrschaft" (Nom.Akk.Sg.ntr.) <
uriir. *kšatrám, aav. tašat̰ ≈ ved. takṣat "zimmert(e)"
(3.Ps.Sg.Aor.Inj.Akt.) < uriir. *taćšat oder aav. aēibiiō ≈
ved. ebhyaḥ "ihnen" (Dat.Pl.) < uriir. *ai̯bʰi̯as herausgegriffen
werden.
Die lautlichen Veränderungen, die bei der Entwicklung der überlieferten einzelsprachlichen
Formen eingetreten sind, lassen sich zunächst ohne Rücksicht auf eine Verarbeitbarkeit
mit dem Computer wie folgt umreißen:
2.1. Gegenüber der Vorform *kšatrám haben sich in avest. xšaϑrəm a) die beiden Verschlußlaute k und t zu den homorganen Frikativen x und ϑ entwickelt, b) erscheint vor dem (auslautenden) Nasal -m das ursprüngliche a zu ə gewandelt, c) ist vermutlich der Wortakzent von der letzten auf die vorletzte Silbe gerückt. In ved. kṣatrám ist die anzusetzende Vorform demgegenüber nahezu unverändert erhalten geblieben; lediglich die Artikulation des Sibilanten mag sich in Richtung auf ein retroflexes ṣ verlagert haben, und zu berücksichtigen ist die Varianz des auslautenden Konsonanten m unter Sandhibedingungen. Die avest. Veränderung der Verschlußlaute läßt sich als éin Schritt auffassen, wenn man davon ausgeht, daß sich bei k wie bei t in der Stellung vor folgendem Konsonanten jeweils ein un dasselbe Merkmal verändert hat, nämlich eben das Merkmal "Okklusion"; dies läßt sich schematisch etwa durch Verwendung von Coversymbolen in einer Formel wie
| K > X /_C |
Auch die Akzentverlagerung und die Vokalveränderung in avest. xšaϑrəm
sind in Formelgestalt darstellbar, wobei es keine Rolle spielt, ob sie eine für
das Phonemsystem des Avestischen relevante Erscheinung darstellen oder lediglich
die "letzte", zur Zeit der schriftlichen Niederlegung geltende phonetische Realisation
widerspiegeln (oder sogar nur die graphische Repräsentation durch die Avestaschrift
betreffen).
Über die Frage der zeitlichen Aufeinanderfolge der einzelnen Veränderungen soll
hier noch nicht im einzelnen präjudiziert werden. Es dürfte jedoch klar sein,
daß die Veränderung der Verschlußlaute zu Frikativen in ein frühes Stadium fällt,
da sie bereits uriranisch ist; diese Information müßte dem
Computerprogramm in geeigneter Form "mitgeteilt" werden.
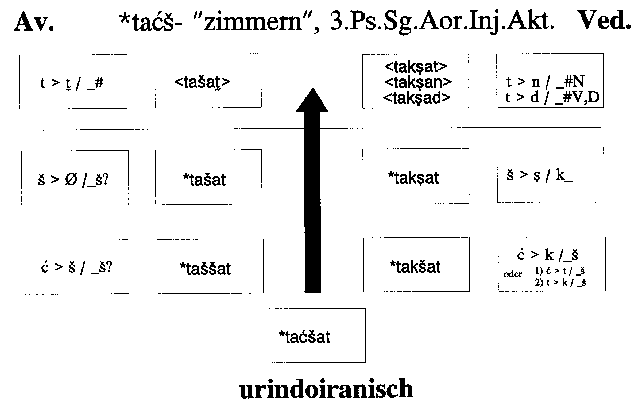
2.2. Ähnliches gilt für die Veränderungen, die uriir. *taćšat betroffen
haben dürften. Hier kommen jedoch auf vedischer Seite umfangreichere Entwicklungen
in Betracht, die zunächst die inlautende Konsonantengruppe betreffen, also den
anzusetzenden Cluster *-ćš- in *taćšat, der ebenso wie *kš
in *kšatrám letztlich in ein ved. *-kṣ- mündete. Je nachdem,
ob man die vorauszusetzende Entwicklung von einer Affrikate -ć- zu dem velaren
Okklusiv -k- als éinen Veränderungsschritt oder als eine Folge zweier Schritte
auffaßt (zuerst Desaffrizierung von -ć-, dann Velarisierung zu -k-),
ergeben sich unterschiedliche Darstellungsmöglichkeiten; ob es Evidenz dafür gibt,
daß eine der beiden Möglichkeiten vorzuziehen ist, muß sich erst noch erweisen.
Auf vedischer Seite ist bei der gegebenen Wortform weiter wieder die Sandhivariation
zu berücksichtigen, die sich darin manifestiert, daß an der überlieferten "Oberfläche"
letztlich drei Formen nebeneinander erscheinen, je nachdem, ob der Form ein Wort
mit Nasal, mit sonstigem stimmhaftem Anlaut (Vokal oder stimmhafter Konsonant),
mit anderem Anlaut oder gar kein Wort folgt (Pausastellung).
Bei avest. tašat̰ ist zunächst die Entwicklung des inlautenden Clusters
ćš zu einfachem š zu berücksichtigen, die sich vermutlich ebenfalls
als Folge zweier Schritte, nämlich a) einer Assimilation zu (geminiertem) šš
und b) einer Degeminierung von šš zu einfachem š auffassen läßt.
Zu klären bleibt in diesem Zusammenhang, ob es möglicherweise eine Evidenz dafür
gibt, daß sich das aus *ćš entstandene avest. š insofern noch
wie eine Geminate verhält,
daß es im Metrum Position bildet. Unproblematisch, da regelmäßig, ist demgegenüber
die Repräsentation von auslautendem *-t als -t̰.
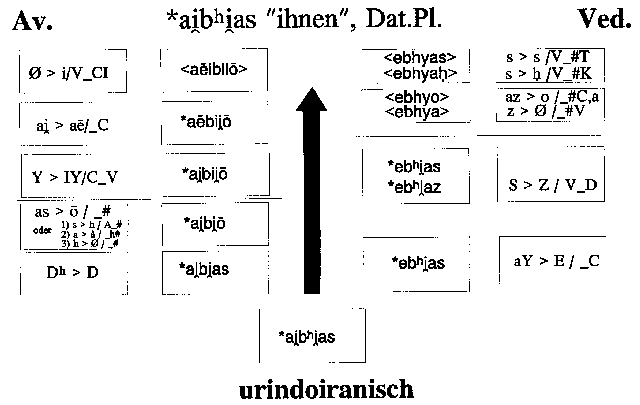
2.3. Noch umfangreichere Veränderungen sind für das Etymon *ai̯bʰi̯as anzunehmen.
Im Avest. sind dies: a) die Desaspiration ursprünglicher Mediae Aspiratae (bzw.
ihr Zusammenfall mit den homorganen Mediae); b) die Veränderung von auslautendem
*-as zu -ō, die auf verschiedene Weise interpretierbar und darstellbar
ist. So könnte sich -as z.B. zunächst mit der allgemeinen Entwicklung von
s > h zu -ah entwickelt haben, danach wäre eine "Velarisierung"
von a zu å vor -h und der Verlust des auslautenden -h
wie auch in *-ās > 〈å̄〉 eingetreten. Oder soll man zunächst
eine Entwicklung von *-as zu *-az annehmen, wie sie für das Vedische
wahrscheinlich ist? Zieht man wiederum die Verhältnisse der anderen iranischen
Sprachen, insbesondere des Altpersischen zurate, so spricht alles für die erstere
Lösung. Weiter ist c) die Entwicklung eines homorganen silbentragenden Vokals in
der Stellung zwischen Konsonant und i̯ bzw. u̯ zu berücksichtigen,
hier *ai̯bi̯ō > *ai̯bii̯ō; diese Entwicklung hat auf die
metrische Gestalt offenbar keinen Einfluß mehr genommen und kann so bereits als
eine sekundäre, im Laufe der Überlieferung eingetretene Oberflächenerscheinung
angesehen werden, muß aber gleichwohl erfaßt werden. Als viertes ist d) die —
als assimilatorische Senkung von i zu ē nach a auffaßbare
— Realisierung des Diphthongs *ai̯ als aē zu nennen; und als fünftes
e) die "epenthetische" Entwicklung eines i vor einem i der Folgesilbe.
Diese letztere Entwicklung muß innerhalb der relativen Chronologie spät angesiedelt
werden, da das epenthetische i und ursprüngliche ai-Diphthonge, wenn
die Überlieferung nicht trügt, nicht zusammengefallen sind.
Bei der ved. Vertretung kommt zunächst die Monophthongierung von *ai̯ zu
〈e〉 in Betracht, dann die vielfaltigen Veränderungen, die den Auslaut
im Hinblick auf die an der Oberfläche erscheinenden Sandhivarianten betreffen.
Hier ist am ehesten von einer anfänglichen Zweiteilung auszugehen, bei der vor
stimmhaftem Anlaut des Folgewortes eine Variante mit auslautendem -z entstand,
aus der sich im weiteren die bezeugten Sandhivarianten ebhyo und ebhya
entwickelten.
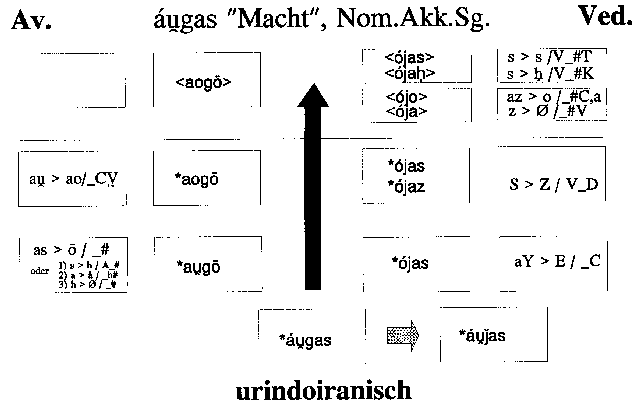
2.4. Keine auf rein lautgesetzlichen Veränderungsschritten beruhende Diversifikation
läßt sich demgegenüber für Wortformenpaare wie avest. aogō / ved. ójas-
"Macht" annehmen. Hier dürfte vielmehr gegenüber der anzusetzenden Ausgangsform
*áu̯gas auf ved. Seite zunächst eine analogische
Veränderung eingetreten sein, durch die an der Stelle des (vor späturiir. -as
< uridg. *-os zu erwartenden) *g ein *ǰ in die Form eingeführt
wurde, das lautgesetzlich nur in denjenigen Kasus zu erwarten wäre, wo späturiir.
-as- < uridg. *-es- vertritt.
3. Soweit einige Beispiele, die die zu gewärtigenden Probleme exemplifizieren sollen.
Will man derartige Prozesse nun computergerecht abbildbar machen, so sind verschiedene
Verfahren denkbar.
3.1. Das nächstliegende Verfahren würde darin bestehen, zunächst die anzunehmenden Einzelschritte, die das Avestische bzw. Vedische betreffen, aufgrund des in der Fachliteratur bereits behandelten unstrittigen Materials zu sammeln (im Sinne einer Datenbank), um sie dann sukzessive auf die Einzelfälle "anzuwenden", indem die betreffenden Wortformen rekursiv immer wieder Zeichen für Zeichen analysiert werden ("Parsing"). Im konkreten Falle würde so etwa durch die (sukzessiv-zweimalige) Anwendung der Regel
| K > X / _C |
| ć > š /_š |
Zu klären ist in diesem Zusammenhang zunächst, in welcher Form die lautgesetzlichen
Entwicklungen sinnvoll in eine Datenbank übergeführt werden können. Sollte sich
herausstellen, daß sämtliche zu erfassenden Regeln über die drei Elemente "Inputlautstruktur",
"Outputlautstruktur", "Umgebungsbedingung(en)" beschreibbar sind, wobei diese jeweils
einen oder mehrere durch Zeichen dargestellbare Einzellaute oder durch Coversymbol
darstellbare Merkmale umfassen, so wäre das für die Schaffung von Parsingbedingungen
eine denkbare Grundlage.
3.2. Dieses Verfahren hat allerdings bereits dadurch enge Grenzen, daß es von sich
aus keinerlei Rückschlüsse auf die relative Chronologie der einzelnen Schritte
erlaubt. So würde das Verfahren bei den ved. Beispielen nicht zum erwünschten
Ziel führen, wenn man die Regel, die die Sandhivariante -o < *-az
entwickelt, vor der Regel anwenden würde, die *-az aus *-as
erzeugt. Es wäre also auf jeden Fall erforderlich, die relative Chronologie, soweit
sie sich unmittelbar aus dem Regelablauf selbst ergibt, bereits bei der Ablage der
Regeln in der zu verarbeitenden Datenbank zu berücksichtigen.
4. Das eigentliche zu lösende Problem besteht nun darin, daß das zu
erzeugende Computerprogramm letztlich nicht nur den historischen Weg vom Urindoiranischen
zu den bezeugten Sprachen nachbilden, sondern "selbständig" auch die Querverbindung
zwischen avestischen und vedischen Wortformen herstellen können soll; mit anderen
Worten, das Programm soll in der Lage sein, avest. xšaϑrəm auch ohne die
explizite Vorgabe von uriir. *kšatrám als mutmaßliche Kognate von ved.
kṣatrám zu erkennen. Dazu ist es erforderlich, den als Folge lautgesetzlicher
Entwicklungen darstellbaren Weg zunächst umzukehren, d.h., von ved. kṣatrám
aus "abwärts" auf dessen mutmaßliche Vorform *kšatrám zu schließen,
um erst dann wieder "aufwärts" zu av. xšaϑrəm zu gelangen, wie in der
Abbildung dargestellt.
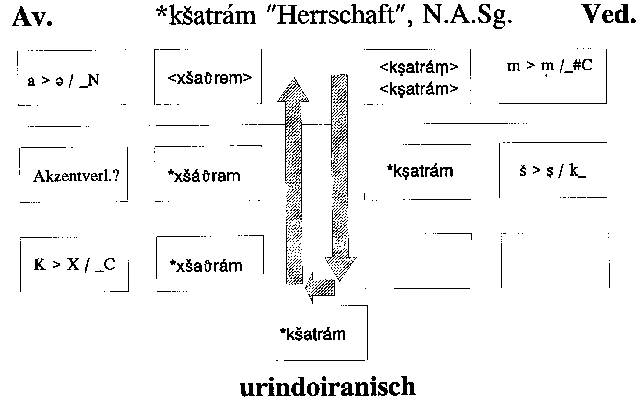
Während der "Abwärtsentwicklung" setzt dies allerdings eine "umgekehrte" Anwendung der Lautregeln voraus, die, wie gesagt, v.a. mit einer besonderen Schwierigkeit behaftet ist: Überall dort, wo durch eine lautliche Entwicklung zwei ursprünglich unterschiedliche Konstellationen zusammengefallen sind, ist die Entwicklung irreversibel, da keine Eindeutigkeit mehr besteht. So ist im genannten Beispiel, von ved. kṣatrám ausgehend, nicht eindeutig "vorhersagbar", ob die Konstellation kṣ auf ein uriir. *kš zurückgeht, dem im Avest. ein xš entsprechen würde, oder ob ein uriir. *ćš wie in takṣat vorliegt, das im Avest. durch š vertreten ist; die Regel
| ć > k /_š |
4.1. Die Grundlage für einen solchen Datenpool ist mit der elektronischen Aufbereitung
des Rigveda und des Avestacorpus zu großen Teilen bereits gegeben. Von beiden Textsammlungen
stehen der Fachwelt heute — über den "Thesaurus Indogermanischer Text- und Sprachmateralien"
— bereits recht zuverlässige elektronische Fassungen zur Verfügung, von denen
diejenige des RV auf eine vergleichsweise lange Geschichte zurückblicken kann:
Der bereits in den 70er Jahren auf einer Großrechneranlage der Universität Texas
eingegebene Text wurde zunächst von verschiedenen Bearbeitern unterschiedlichen
Korrekturen unterzogen. Mit der Schaffung einer dem Padapāṭha nahekommenden sandhifreien
Variante durch Aleksandr Lubotsky, der damit die Grundlage für seine demnächst
erscheinende RV-Konkordanz
legte, ist der Text einer Analyse im Hinblick auf einzelne Wortformen bereits wesentlich
besser zugänglich gemacht. Eine weitere Neubearbeitung, die nützliche Zusatzinformationen
enthält, ist der "metrically restored text", den Barend van Nooten und Gary B.
Holland vorgelegt haben. Auch das elektronische Avestacorpus hat bereits eine längere
Entstehungsgeschichte: Nachdem es in den Jahren 1985 bis 1988 durch Sonja Fritz
eingegeben und zwischenzeitlich durch verschiedene Beiträger korrigiert und ergänzt
wurde, unterliegt es derzeit einer neuerlichen Überarbeitung durch Michiel de Vaan.
Dabei geht es darum, zusätzlich zu dem kritischen Text, wie er in Geldners Ausgabe
niedergelegt ist, auch den bisher noch nicht eingegebenen Variantenapparat zu erfassen;
darüber hinaus sollen Konjekturen und Emendationen verschiedener anderer Bearbeiter
Berücksichtigung finden. Erforderlich ist dieser Zusatzaufwand im Hinblick auf
die Zielsetzung des Projekts deshalb, weil weder die Geldnersche Ausgabe noch sonst
irgendeine existierende Bearbeitung die aus der handschriftlichen Überlieferung
zu gewinnenden Informationen mit letzter Konsequenz ausgeschöpft hat. Durch die
neuerliche Durchsicht der Lesarten soll der elektronische Text, soweit es möglich
ist, an den präsumptiven sasanidischen Archetypus angenähert werden, um so eine
geeignete Materialbasis für AUREA zu schaffen.
Auch im Bereich des Rigveda sind noch erhebliche Vorarbeiten erforderlich. Dies
betrifft v.a. eine Auswertung, bei der die Angaben über das metrische Verhalten
der Wortformen und den ursprünglichen — d.h. nicht erst durch die redaktionelle
Bearbeitung in den Text gelangten — Sandhigebrauch zusammengeführt werden, um
so die tatsächliche, bei Abfassung der Lieder geltende Lautstruktur der Wortformen
zu ermitteln. Mithilfe eines eigenen Computerprogramms, das im Sinne eines "Parsers"
die drei vorliegenden elektronischen Versionen analysiert und miteinander abgleicht,
kann man diesem Ziel bereits recht nahekommen. Daß dabei nicht nur eine Stringenzprüfung
der elektronischen Texte selbst abfällt, sondern auch einige bemerkenswerte neue
Erkenntnisse etwa im Hinblick auf im metrischen Verhalten nachwirkende Laryngale,
ist ein erfreuliches Nebenresultat.
Erforderlich bleibt für die rigvedischen wie auch für die avestischen Wortmaterialien
jedoch noch eine weitere Ergänzung, bevor sie einem die Lautgesetze abbildenden
AUREA-Programm als Vergleichsbasis dienen können, nämlich eine morphologische
und semantische Bestimmung der einzelnen Wortformen. Beide sind in den bisherigen
Bearbeitungen nicht enthalten und beide können nur zum geringeren Teil durch einen
elektronischen Automatismus hinzugefügt werden. Hieran wird zur Zeit gearbeitet.
5. Nach einem weiteren Ausbau des Datenmaterials sollte es letztlich möglich sein, über das Vedische und Avestische hinaus Daten aus weiteren indoiranischen und indogermanischen Sprachen in die Entscheidungsfindung einzubeziehen. Eine "Schnittstelle" zu einer umfassenden indogermanistischen Regel- und Wortformendatenbank ist bereits von Anfang an vorgesehen; es wird jedoch einige Zeit brauchen, bis sie wird realisiert werden können.